There has been a lot of discussion lately about the NetApp deduplication technology, especially on twitter. We had a lot of misinformation and FUD flying around, so I thought that a blog entry that takes a close look at the technology was in order.
But first a bit of disclosure, I currently work for a storage reseller that sells NetApp as well as other storage. The information in this blog posting is derived from NetApp documents, as well as my own personal experience with the technology at our customer sites. This posting is not intended to promote the technology as much as it is to explain it. The intent here is to provide information from an independent perspective. Those reading this blog post are, of course, free to interpret it the way they choose.
How NetApp writes data to disk.
First lets talk about how the technology works. For those who aren't familiar with how a NetApp array stores data on disk, here's the key to understanding how NetApp approaches writes. NetApp stores data on disk using a simple file system called WAFL (Write Anywhere File Layout). The file system stores metadata which contains information about the data blocks, has inodes that point to indirect blocks, and indirect blocks point to the data blocks. One other thing that should be noted about the way that NetApp writes data is that the controller will coalesce writes into full stripes when ever possible. Furthermore, the concept of updating a block is unknown in the NetApp world. Block updates are simply handled as new writes, and the pointers to the updated blocks are moved to point to the new "updated" block.
How deduplication works.
First, it should be noted that NetApp deduplication operates on a volume level. In other words,all of the data within a single NetApp volume is a candidate for deduplication. This includes both file data, and block (LUN) data that is stored within that Netapp volume. NetApp deduplication is a post-process that occurs based on either a watermark for the volume, or on a schedule. For example, if the volume exceeds 80% of it's capacity a deduplication run can be started automatically. Or, a deduplication run can be started at a particular time of day, usually at a time when the user thinks the array will be less utilized.
The maximum sharing for a block is 255. This means that if there are 500 duplicate blocks,there will be 2 blocks actually stored with 1/2 of the pointers pointing to the first block and 1/2 of the pointers pointing to the second block. Note that this 255 maximum is separate from the 255 maximum for snapshots.
When deduplication runs for the first time on a NetApp volume with existing data, it scans the blocks in the volume and creates a fingerprint database, which contains a sorted list of all fingerprints for used blocks in the volume. After the fingerprint file is created, fingerprints are checked for duplicates, and, when found, first a byte- by-byte comparison of the blocks is done to make sure that the blocks are indeed identical. If they are found to be identical, the block‘s pointer is updated to the already existing data block, and the new (duplicate) data block is released. Releasing a duplicate data block entails updating the indirect inode pointing to it, incrementing the block reference count for the already existing data block, and freeing the duplicate data block.
As new data is written to the deduplicated volume, a fingerprint is created for each new block and written to a change log file. When deduplication is run subsequently, the change log is sorted, its sorted fingerprints are merged with those in the fingerprint file, and then the deduplication processing occurs as described above. There are two change log files, so that as deduplication is running and merging the new blocks from one change log file into the fingerprint file, new data that is being written to the flexible volume is causing fingerprints for these new blocks to be written to the second change log file. The roles of the two files are then reversed the next time that deduplication is run. (For those familiar with Data ONTAP usage of NVRAM, this is analogous to when it switches from one half to the other to create a consistency point.) Note that when deduplication is run an an empty volume, the fingerprint file is still created from the log file.
Performance of NetApp deduplication.
There has been a lot of discussion about the performance of Netapp deduplication. In general, deduplication will use CPU and memory in the controller. How much CPU will be ustilied is very had to determine ahead of time, however in general you can expect to use from 0% to 15% of the CPU in most cases, but as much as 50% has been observed in some cases. The impact of deduplication on a host or application can very significantly and depends on a number of different factors including:
• The application and the type of dataset being used
• The data access pattern (for example, sequential versus random access, the size and pattern of the
• I/O)
• The amount of duplicate data, the compressibility of the data, the amount of total data, and the
• average file size
• The nature of the data layout in the volume
• The amount of changed data between deduplication runs
• The number of concurrent deduplication processes and compression scanners running
• The number of volumes that have compression/deduplication enabled on the system
• The hardware platform—the amount of CPU/memory in the system
• The amount of load on the system
• Disk types ATA/FC, and the RPM of the disk
• The number of disk spindles in the aggregate
The deduplication is a low priority process, so host I/O will take precedence over dedupllication. However, all of the items above will effect the performance of the deduplication process itself. In general you can expect to get somewhere between 100MB/sec to 200/MB/sec of data dedupication from a NetApp controller.
The effect of deduplication on the write performance of a system is very dependent on the model of controller and the amont of load that is being put on the system. For deduplicated volumes, if the load on a system is low—that is, for systems where the CPU utilization is around 50% or lower—there is a negligible difference in performance when writing data to a deduplicated volume, and there is no noticeable impact on other applications running on the system. On heavily used systems, however, where the system is nearly saturated, the impact on write performance can be expected to be around 15% for most models of controllers.
Read performance of a deduplicated volume depends on the type of reads being performed. The implicit on random reads is negligible. In early versions of ONTAP the impact of deduplication was noticeable with heavy sequential read applications. However with version 7.3.1 and above NetApp added something they called "intelligent cache" to ONTAP specifically to help with the performance of sequential reads on deduplicated volumes and were able to mitigate the performance impact of sequential reads nearly completely. Finally, with the addition of FlashCache cards to a controller, performance of deduplicated volumes can actually be better than non-deduplicated volumes.
Deuplication Interoperability with Snapshots.
Snapshots and their interoperability with deduplication has been a hotly debated topic on the internet lately. Snapshot copies lock blocks on disk that cannot be freed until the Snapshot copy expires or is deleted. On any volume, once a Snapshot copy of data is made, any subsequent changes to that data temporarily require additional disk space, until the snapshot is deleted or expires. The is true with deduplicated volumes as well as non-deduplicated volumes. Thus the space savings from deuplication for any data held by a snapshot prior to a deduplication run will not be recognized until after that snapshot expires or is deleted.
Some best practices to achieve the best space savings from deduplication-enabled volumes that contain Snapshot copies include:
• Run deduplication before creating new Snapshot copies.
• Limit the number of Snapshot copies you maintain.
• If possible, reduce the retention duration of Snapshot copies.
• Schedule deduplication only after significant new data has been written to the volume.
• Configure appropriate reserve space for the Snapshot copies.
Some Application Best Practices
VMWare
In general VMware deduplicates well, especially if a few best practices in laying out the VMDK files are considered. The following best practices should be considered for VMware implementations:
• Operating system data deduplicates very well therefore you should stack as many OS's onto the same volume as possible.
• Keep VM swap files, pagefiles, user and system temp directories on separate VMDK files.
• Utilize FlashCache where ever possible to cache frequently accessed blocks (like those from the OS).
• Always perform proper alignment of your VM's on the NetApp 4K boundaries.
•
Microsoft Exchange
In general deduplication provides little benefit for versions of Microsoft Exchange prior to Exchange 2010. Starting with Exchange 2010 Microsoft has eliminated single instance storage and deduplication can reclaim much of the additional space created by this change.
Backups (NDMP, SnapMirror and SnapVault)
The following are some best practices to consider for backups of deduplicated volumes:
• Ensure deduplication operations initiate only after your backup completes.
• Deduplication operations on the destination volume complete prior to initiating the next backup.
• If backing up data from multiple volumes to a single volume you may achieve significant space savings from deduplication beyond that of the deduplication savings from the source volumes. This is because you are able to run deduplication on the destination volume which could contain duplicate
• data from multiple source volumes.
• If you are backing up data from your backup disk to tape consider using SMTape to preserve the deduplication/compression savings. Utilizing NDMP to tape will not preserve the deduplication savings on tape.
• Data compression can affect the throughput of your backups. The amount of impact is dependent upon the type of data, compressibility, storage system type and available resources on the destination storage system. It is important to test the affect on your environment before implementing
• into production.
• If the application that you are using to perform backups already does compression, NetApp data compression will not add significant additional savings.
Conclusions
In general, NetApp deduplication can help drive down the TCO of your storage systems significantly, especially when combined with FlashCache in a VMware or Virtual Desktop environment. If best practices are followed carefully, the performance impact of deduplication is negligible, and the space savings for some applications can be considerable. Some careful planning and testing in the customers environment are necessary to ensure that maximum advantage is taken of deduplication, however the ability to schedule when the operations take place combined with the ability to turn on and off deduplication provide significant flexibility in to tune the environment for a customer's particular application profile.
Sunday, June 12, 2011
Monday, May 30, 2011
EMC FAST and NetApp FlashCache a Comparison
Introduction
This article is intended to provide the reader with an introduction to two technologies, EMC FAST and NetApp FlashCache. Both of these technologies are intended to improve the performance of storage arrays, while also helping to bend the cost curve of storage downward. With the amount of data that needs to be stored increasing on a daily basis, anything that addresses the cost of storage is a welcome addition to the data center portfolio.
EMC FAST
EMC FAST (Fully Automated Storage Tiering) is actually a suite made of of two different products. the first, called FAST Cache operates by keeping a copy of "hot" blocks of data on SSD drives. In effect it acts as a very fast disk cache for data that is currently being accessed while the data itself is being stored on either 15K SAS or 7200 RPM NL-SAS (SATA) drives.
FAST Cache provides the ability to improve the performance of SATA drives, as well as to turbo charge the performance of fiber channel and SAS drives as well. In general, this kind of technology helps to divide performance from spindle count, which helps drive down the number of drives required for many workloads, thus driving down the cost of storage, and the overall TCO of storage.

The other product in the FAST suite is FAST Virtual Pool. This is the product that most people associate with FAST since it is the one that leverages three different disk technologies, SSD, high speed drives such as 15K RPM SAS, and slower high capacity drives such as 7200 RPM NL-SAS. By placing only data that requires high speed access on the SSD drives, data that is receiving a moderate amount of access on the 15K SAS drives, and putting the rest on the slower, high capacity disks EMC FAST is able to drive the TCO of storage downward.

NetApp FlashCache
NetApp approaches the overall issue of improved performance while simultaneously driving down the TCO of storage in a different way. NetApp believes that using fewer disks to store the same amount of data is the best way to drive down TCO. Therefore NetApp has spent a significant amount of time developing storage efficiency tools to help their customer's store more data in less space. For example, they developed a variant of RAID-6 called RAID-DP which provides the protection and performance of RAID-10, while utilizing significantly less space. NetApp has also developed block level de-duplication which can be utilized with primary production data.
However, as with many technologies of this type there could be a performance penalty paid for it's utilization. Therefore, Netapp needed to develop a way to improve the performance if it's arrays while also supporting it's storage efficiency technology. With the advent of Flash memory, Netapp found a way to do this without any need for significant changes in the architecture of it's arrays. Thus was born FlashCache.
FlashCahce provides a secondary read cache for hot blocks of data. This proves a way to separate performance from spindle count, and thus not only allows workloads intended for Fiber Channel or SAS drives to potentially run on SATA drives, but it also addresses some of the performance issues with the storage efficiency technologies that NetApp developed. For example, with FlashCache utilized in a virtual desktop environment Netapp de-duplication allows many individual Windows images to be represented in a very small footprint on disk. However a problem arrises when a large numer of desktops all try to access their Windows image at once. However with the addition of FlashCache, most, if not all of the Windows image would end up being storage in Flash memory, thus avoiding the performance issue of a boot storm, virus checking storm, etc.

Conclusion
Both EMC and Netapp have developed ways to help both improve the performance, and drive the TCO of storage downward. the two vendors approached the problem is somewhat different ways, but in the end they have both solved the problem in unique and effective ways.
The NetApp technology requires that the user buy-in completely to the NetApp vision of storage efficiency. If the user ignores the advantages of de-dupication in particular, or has data or workloads that simply don't allow for the application of the NetApp storage efficiency technology then the TCO saving that NetApp promises will not be achieved. Utilizing FlashCache to seperate performance from spindle count is also critical in maintaining the performance of the array. This separation of performance from spindle count also in and of itself drives dwn the number ofd drives needed to support a workload, and thus also drives down the TCO.
The EMC technology requires a very good understanding of your application workloads, and careful planning and sizing of the different tiers of storage. EMC could do more to make the two sub-products work together so that a single solution could provide both the TCO and the performance improvements at the same time. However, EMC FAST is a product that provides the TCO improvement promised, and doe it with a clean and elegant solution.
Finally, a little on the future. With the cost of Flash memory coming down 50% year over year, it will soon reach the same price point that we currently see 15K HDD's at. Once that happens one has to wonder what role 15K HHDs will fill? If 15K HDDs are, indeed, squeezed out of existence by this reduction in the price of Flash memory, what purpose will 3 tiered automated storage tiering fill? Or, will the future simply be 2 tiers of storage, one that provides bulk capacity, and one that accelerates the performance of this bult capacity? if that predication is correct, then FAST VP will have a limited life, and FAST Cache and FlashCache will be the longer surviving technology.
This article is intended to provide the reader with an introduction to two technologies, EMC FAST and NetApp FlashCache. Both of these technologies are intended to improve the performance of storage arrays, while also helping to bend the cost curve of storage downward. With the amount of data that needs to be stored increasing on a daily basis, anything that addresses the cost of storage is a welcome addition to the data center portfolio.
EMC FAST
EMC FAST (Fully Automated Storage Tiering) is actually a suite made of of two different products. the first, called FAST Cache operates by keeping a copy of "hot" blocks of data on SSD drives. In effect it acts as a very fast disk cache for data that is currently being accessed while the data itself is being stored on either 15K SAS or 7200 RPM NL-SAS (SATA) drives.
FAST Cache provides the ability to improve the performance of SATA drives, as well as to turbo charge the performance of fiber channel and SAS drives as well. In general, this kind of technology helps to divide performance from spindle count, which helps drive down the number of drives required for many workloads, thus driving down the cost of storage, and the overall TCO of storage.

The other product in the FAST suite is FAST Virtual Pool. This is the product that most people associate with FAST since it is the one that leverages three different disk technologies, SSD, high speed drives such as 15K RPM SAS, and slower high capacity drives such as 7200 RPM NL-SAS. By placing only data that requires high speed access on the SSD drives, data that is receiving a moderate amount of access on the 15K SAS drives, and putting the rest on the slower, high capacity disks EMC FAST is able to drive the TCO of storage downward.

NetApp FlashCache
NetApp approaches the overall issue of improved performance while simultaneously driving down the TCO of storage in a different way. NetApp believes that using fewer disks to store the same amount of data is the best way to drive down TCO. Therefore NetApp has spent a significant amount of time developing storage efficiency tools to help their customer's store more data in less space. For example, they developed a variant of RAID-6 called RAID-DP which provides the protection and performance of RAID-10, while utilizing significantly less space. NetApp has also developed block level de-duplication which can be utilized with primary production data.
However, as with many technologies of this type there could be a performance penalty paid for it's utilization. Therefore, Netapp needed to develop a way to improve the performance if it's arrays while also supporting it's storage efficiency technology. With the advent of Flash memory, Netapp found a way to do this without any need for significant changes in the architecture of it's arrays. Thus was born FlashCache.
FlashCahce provides a secondary read cache for hot blocks of data. This proves a way to separate performance from spindle count, and thus not only allows workloads intended for Fiber Channel or SAS drives to potentially run on SATA drives, but it also addresses some of the performance issues with the storage efficiency technologies that NetApp developed. For example, with FlashCache utilized in a virtual desktop environment Netapp de-duplication allows many individual Windows images to be represented in a very small footprint on disk. However a problem arrises when a large numer of desktops all try to access their Windows image at once. However with the addition of FlashCache, most, if not all of the Windows image would end up being storage in Flash memory, thus avoiding the performance issue of a boot storm, virus checking storm, etc.

Conclusion
Both EMC and Netapp have developed ways to help both improve the performance, and drive the TCO of storage downward. the two vendors approached the problem is somewhat different ways, but in the end they have both solved the problem in unique and effective ways.
The NetApp technology requires that the user buy-in completely to the NetApp vision of storage efficiency. If the user ignores the advantages of de-dupication in particular, or has data or workloads that simply don't allow for the application of the NetApp storage efficiency technology then the TCO saving that NetApp promises will not be achieved. Utilizing FlashCache to seperate performance from spindle count is also critical in maintaining the performance of the array. This separation of performance from spindle count also in and of itself drives dwn the number ofd drives needed to support a workload, and thus also drives down the TCO.
The EMC technology requires a very good understanding of your application workloads, and careful planning and sizing of the different tiers of storage. EMC could do more to make the two sub-products work together so that a single solution could provide both the TCO and the performance improvements at the same time. However, EMC FAST is a product that provides the TCO improvement promised, and doe it with a clean and elegant solution.
Finally, a little on the future. With the cost of Flash memory coming down 50% year over year, it will soon reach the same price point that we currently see 15K HDD's at. Once that happens one has to wonder what role 15K HHDs will fill? If 15K HDDs are, indeed, squeezed out of existence by this reduction in the price of Flash memory, what purpose will 3 tiered automated storage tiering fill? Or, will the future simply be 2 tiers of storage, one that provides bulk capacity, and one that accelerates the performance of this bult capacity? if that predication is correct, then FAST VP will have a limited life, and FAST Cache and FlashCache will be the longer surviving technology.
Friday, May 20, 2011
Flash Storage and Automated Storage Tiering
In recent years, a move toward automated storage tiering has begun in the data center. This move has been inspired by the desire to continue to drive down the cost of storage, as well as the introduction of faster, but more expensive storage in the form of Flash memory in the storage array marketplace. Flash memory is significantly faster than spinning disks, and thus it’s ability to provide very high performance storage has been of interest. However, its cost is considerable, and therefore a way to utilize it and still bend the cost curve downward was needed. Note that Flash memory has been implemented in different ways. It can be obtained as a card for the storage array controller, or as SSD disk drives, and even, as cache on regular spinning disks. However it is implemented, it’s speed and expense remains the same.
Enter the concept of tiered storage again. The idea was to place only that data which absolutely required the very high performance of Flash on Flash, and to leave the remaining data on spinning disk. The challenge with tiered storage in the way that it has been defined in the past was that it meant that too much data would be placed on very expensive Flash since traditionally an entire application would have all it’s data placed on a single tier. Even if only specific parts of the data at the file, or LUN level were placed on Flash, the quantity needed would still be very high, thus driving the costs of for a particular application up. It was quickly recognized that the only way to make Flash cost effective would be to place only the blocks which are “hot” for an application in Flash storage, thereby minimizing the footprint of Flash storage.
The issue addressed by automated storage tiering is that you no longer need to know ahead of time what the proper tier of storage for a particular application’s data needs to be. Furthermore the classification of the data can occur at a much more fine-grained block level rather than the file or the LUN as with some earlier automated storage tiering implementations.
Flash has changed the landscape of storage for the enterprise. Currently, Fash/SSD storage can cost 16-20X what Fiber channel, SAS, or SATA storage can cost. The dollars per GB model ends up looking something like the following:

However the IOPS per $ model looks more like this:

The impact on the tiered storage architectural model of Flash storage has been, in effect, to add a tier-0 level of storage where application data is placed that requires extremely fast random I/O performance. Typical examples of such data are database index tables or key lookup tables, etc. Placing this kind of data, which may only be part of an application’s data, on Flash storage can often have a dramatically positive effect on the performance of an application. However, due to the cost of Flash storage the question is often raised, how can data centers ensure that only data that requires this level of performance resides on SSD or Flash storage so that they can continue to contain costs? Furthermore, is there a way to put only the “hot” parts of the data in the very expensive tier-0 capacity, and leave less hot, and cold data in slower, less expensive capacity? Block based automated storage tiering is the answer to these questions.
Different storage array vendors have approached this problem in different ways. However, in all cases, the object is to place data at a block level, on tier-0 or Flash storage only while that data is actually being accessed, and then to store the rest of the data on lower tiered storage while the data is at rest. Note that this movement must be done at the block level in order to avoid performance issues, and to truly minimize the capacity of the tier-0 storage.
One approach used by several storage vendors is to move blocks of data between multiple tiers of storage via a policy. For example, the policy might dictate that writes always occur to tier-0, and then if that data is not read immediately it is moved to tier-1. Then if the data isn’t read for 3 months that data is then moved to tier-2. The policy might also dictate that if the data is then read from the tier-2 disk then it is placed back on tier-0 in case additional reads are required and the entire process starts all over again. Logically this mechanism provides what enterprises are looking for, minimizing tier-0 storage and placing blocks of data on the lowest-cost storage possible. The challenge with this approach is that the I/O profile of the application needs to be well understood when the policies are developed in order to avoid accessing data from tier-2 storage too frequently and generally moving data up and down the stack too often since this movement is not “free” from a performance perspective. Additionally, EVT has found that for most customers, data rarely needs to spend time in tier-1 (FC or SAS) storage, that most of the data ends up spending most of it’s live on the SATA storage.
Therefore as the cost of Flash storage continues to come down, the need for the SAS or Fiber Channel storage will continue to decline, and eventually disappear leaving just Flash and SATA storage in most arrays.
Another approach that at least one storage vendor is using is to avoid all the policy based movement and to treat the Flash storage as a large read cache. This places the blocks that are most used on tier-0, and leaves the rest on spinning disk. When the fact that the sequential write performance of Flash, SAS/FC, and SATA is similar is taken into consideration along with a controller that orders its random writes, this approach can provide a much more robust way to implement Flash storage. In some cases, it allows an application that would not normally be considered a good candidate for SAS or Fiber Channel storage to be able to utilize SATA disks instead. In general, this technique de-couples spindle count from performance thus providing more subtle advantages as well. For example, applications which has traditionally required very small disk drives so that the spindle could would be might (many, many 146GB FC drives, for example) can now be run on much higher capacity 600GB SAS drives and still provide the same, or better performance.
Overall, automated storage tiering is becoming a de-facto standard in the storage industry. However different storage array vendors have taken very different approaches to the implementation of automated tiering, but in the end the result is uniformly the same. The ability of the enterprise to purchase Flash storage to help improve the performance of their applications while at the same time continuing to bend the cost curve of storage downward.
Enter the concept of tiered storage again. The idea was to place only that data which absolutely required the very high performance of Flash on Flash, and to leave the remaining data on spinning disk. The challenge with tiered storage in the way that it has been defined in the past was that it meant that too much data would be placed on very expensive Flash since traditionally an entire application would have all it’s data placed on a single tier. Even if only specific parts of the data at the file, or LUN level were placed on Flash, the quantity needed would still be very high, thus driving the costs of for a particular application up. It was quickly recognized that the only way to make Flash cost effective would be to place only the blocks which are “hot” for an application in Flash storage, thereby minimizing the footprint of Flash storage.
The issue addressed by automated storage tiering is that you no longer need to know ahead of time what the proper tier of storage for a particular application’s data needs to be. Furthermore the classification of the data can occur at a much more fine-grained block level rather than the file or the LUN as with some earlier automated storage tiering implementations.
Flash has changed the landscape of storage for the enterprise. Currently, Fash/SSD storage can cost 16-20X what Fiber channel, SAS, or SATA storage can cost. The dollars per GB model ends up looking something like the following:
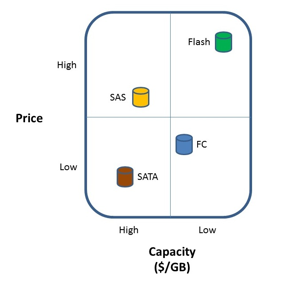
However the IOPS per $ model looks more like this:

The impact on the tiered storage architectural model of Flash storage has been, in effect, to add a tier-0 level of storage where application data is placed that requires extremely fast random I/O performance. Typical examples of such data are database index tables or key lookup tables, etc. Placing this kind of data, which may only be part of an application’s data, on Flash storage can often have a dramatically positive effect on the performance of an application. However, due to the cost of Flash storage the question is often raised, how can data centers ensure that only data that requires this level of performance resides on SSD or Flash storage so that they can continue to contain costs? Furthermore, is there a way to put only the “hot” parts of the data in the very expensive tier-0 capacity, and leave less hot, and cold data in slower, less expensive capacity? Block based automated storage tiering is the answer to these questions.
Different storage array vendors have approached this problem in different ways. However, in all cases, the object is to place data at a block level, on tier-0 or Flash storage only while that data is actually being accessed, and then to store the rest of the data on lower tiered storage while the data is at rest. Note that this movement must be done at the block level in order to avoid performance issues, and to truly minimize the capacity of the tier-0 storage.
One approach used by several storage vendors is to move blocks of data between multiple tiers of storage via a policy. For example, the policy might dictate that writes always occur to tier-0, and then if that data is not read immediately it is moved to tier-1. Then if the data isn’t read for 3 months that data is then moved to tier-2. The policy might also dictate that if the data is then read from the tier-2 disk then it is placed back on tier-0 in case additional reads are required and the entire process starts all over again. Logically this mechanism provides what enterprises are looking for, minimizing tier-0 storage and placing blocks of data on the lowest-cost storage possible. The challenge with this approach is that the I/O profile of the application needs to be well understood when the policies are developed in order to avoid accessing data from tier-2 storage too frequently and generally moving data up and down the stack too often since this movement is not “free” from a performance perspective. Additionally, EVT has found that for most customers, data rarely needs to spend time in tier-1 (FC or SAS) storage, that most of the data ends up spending most of it’s live on the SATA storage.
Therefore as the cost of Flash storage continues to come down, the need for the SAS or Fiber Channel storage will continue to decline, and eventually disappear leaving just Flash and SATA storage in most arrays.
Another approach that at least one storage vendor is using is to avoid all the policy based movement and to treat the Flash storage as a large read cache. This places the blocks that are most used on tier-0, and leaves the rest on spinning disk. When the fact that the sequential write performance of Flash, SAS/FC, and SATA is similar is taken into consideration along with a controller that orders its random writes, this approach can provide a much more robust way to implement Flash storage. In some cases, it allows an application that would not normally be considered a good candidate for SAS or Fiber Channel storage to be able to utilize SATA disks instead. In general, this technique de-couples spindle count from performance thus providing more subtle advantages as well. For example, applications which has traditionally required very small disk drives so that the spindle could would be might (many, many 146GB FC drives, for example) can now be run on much higher capacity 600GB SAS drives and still provide the same, or better performance.
Overall, automated storage tiering is becoming a de-facto standard in the storage industry. However different storage array vendors have taken very different approaches to the implementation of automated tiering, but in the end the result is uniformly the same. The ability of the enterprise to purchase Flash storage to help improve the performance of their applications while at the same time continuing to bend the cost curve of storage downward.
Subscribe to:
Comments (Atom)